UNIQUE(ユニーク)関数の使い方
Yujiro Sakaki
榊裕次郎の公式サイト – Transparently
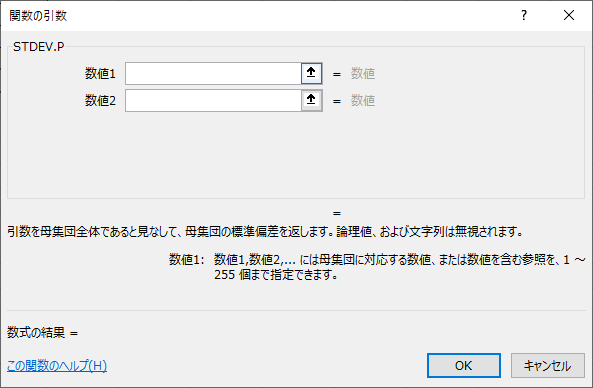
STDEV.P(スタンダードディービエーション・ピー)関数のPは、ポピュレーション(母集団)を意味し、母集団に対しての標準偏差を求めます。
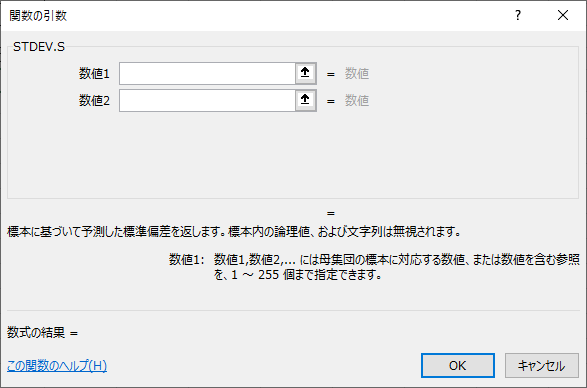
SEDEV.S(スタンダードディービエーション・エス)関数のSは、サンプル(標本)を意味し、標本に対して、母集団の標準偏差を推定する標準偏差を求めます。
【構文】
=STDEV.P(数値1, 数値2……)
=STDEV.S(数値1, 数値2……)
【使用例】
[char no=”1″ char=”さえちゃん1”]標準偏差を勉強する際には、必ず分散のVAR関数をしっかりと学習してください。VAR関数の平方根がSTDEV関数の値になります。そのため、分散同様、母集団の標準偏差、標本の標準偏差(標本標準偏差)、不偏標準偏差と使い分けがあります。[/char]
分散で説明したときのデータを使いましょう。セルE5には、VAR.P関数が入っています。
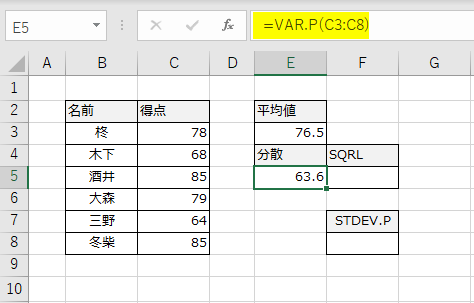
これをSQRL関数で平方根を出力してみます。
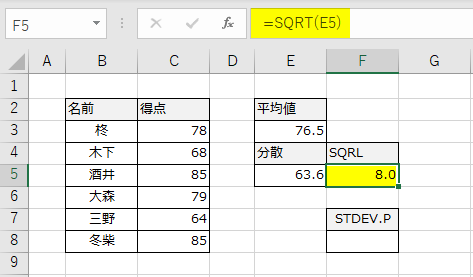
分散の平方根が標準偏差になります。この作業をSTDEV.P関数を使って求めてみましょう。この関数は、[数式]タブ→関数ライブラリ[その他の関数]→[統計]の中にあります。
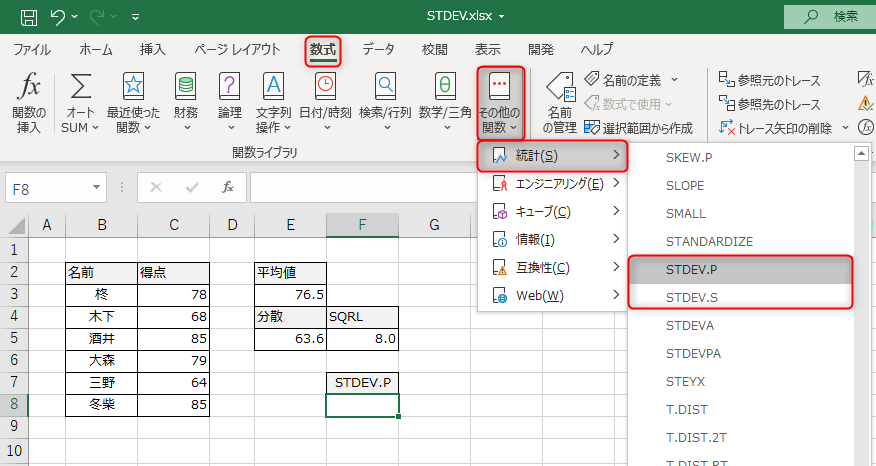
使い方は、SUM関数と同じです。標準偏差を出したい範囲を選択します。
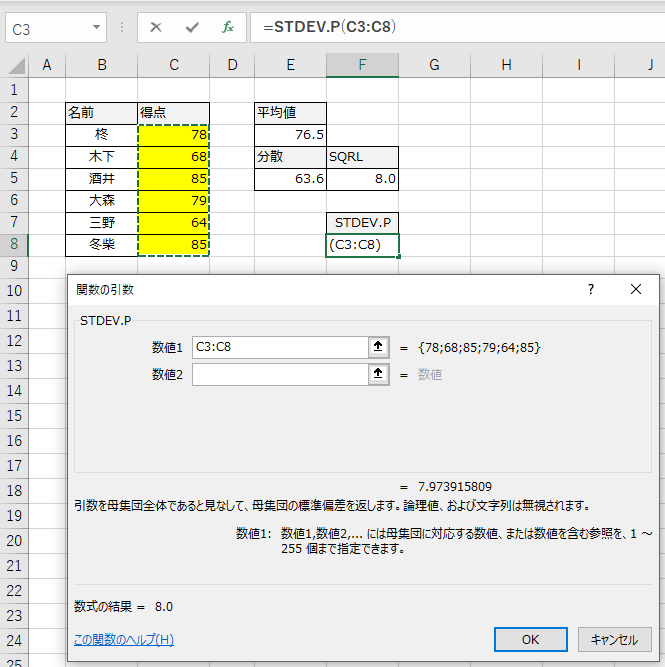
これで先ほどと同じ数値が出ました。
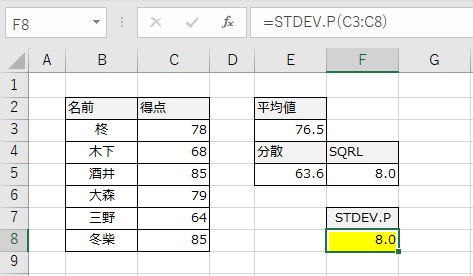
繰り返しになりますが、STDEV.PとSTDEV.Sの違いは、VAR関数の理解が鍵となります。
STDEV関数は、標準偏差という結果をすぐに出力してしまうので、標準偏差を出力するための計算フローを知らずに使用した場合、誤った使い方をしてしまいがちです。
使用するデータにSTDEV.PとSTDEV.Sどちらが適切か? は、しっかりと考えて使ってください。
[char no=”4″ char=”さえちゃん3”]標準偏差で出力される値を「σ(小文字のシグマ)」で表します。1σには約68%のデータが集まっていて、2σには約95%、3σには約99%のデータが含まれているよ~というのは暗記しちゃってください。[/char]
標準偏差を学習するときは、こちらの正規分布を思い描いてください。中心を平均値として前後の-1.0 +1.0 の範囲が、標準偏差の-1σ+1σの範囲になります。
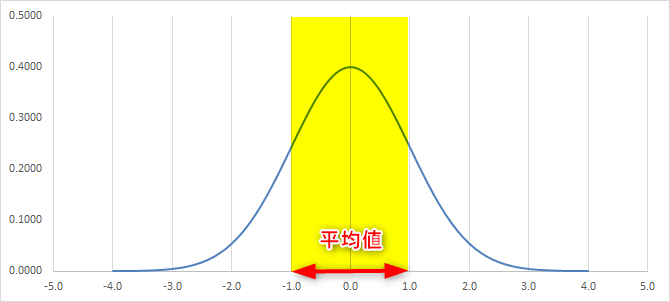
つまり、平均が「70」で、標準偏差が「5」と出力された場合は、65~75の間にデータが約68%ありますよ~という意味になります。
もちろん、データによってはこの山が右寄りだったり、左寄りだったり、凹型のようなふた山型だったりするわけですが、世の中のデータはこの正規分布にだいたい収まるとされています。
正規分布に収まる代表的なデータは、日本人の身長です。
総務省からひっぱってきたデータを整理してまとめると、身長167cm~168cmの凹みはすこし気になりますが、先ほどの正規分布とよく似ています。
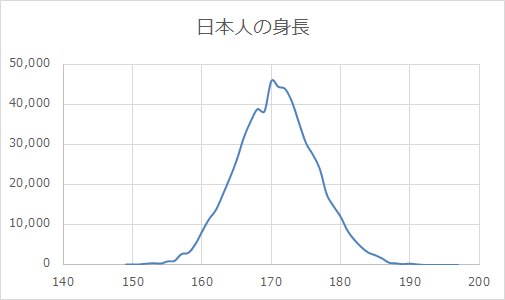
こういう情報がわかると、例えば、S・M・Lサイズの洋服はどのくらい作ればいいのか? とか、座席シートの設計の際にどの程度の空間があればリラックスできるのか? とか、そういった業務における最適なアクションがとれるようになりますよね。
データから情報を読み取る作業フローは、このような感じです。
統計
=STDEV.P(数値1, 数値2……)
=STDEV.S(数値1, 数値2……)